AI behavior,
controlled.

Trusted by Fortune 500s







Available to teams everywhere.
.avif)
.png)
human <> AI alignment
.png)
.png)
Less runtime improvisation,
more upstream control.
.avif)
Interoperable by design

.jpg)
Control AI behavior across users, teams, and time.
.png)
Turn packaged expertise into reusable AI behavior
Work-safe & secure
.svg)
.svg)
.svg)
.svg)


Trusted by enterprises
.svg)
.svg)
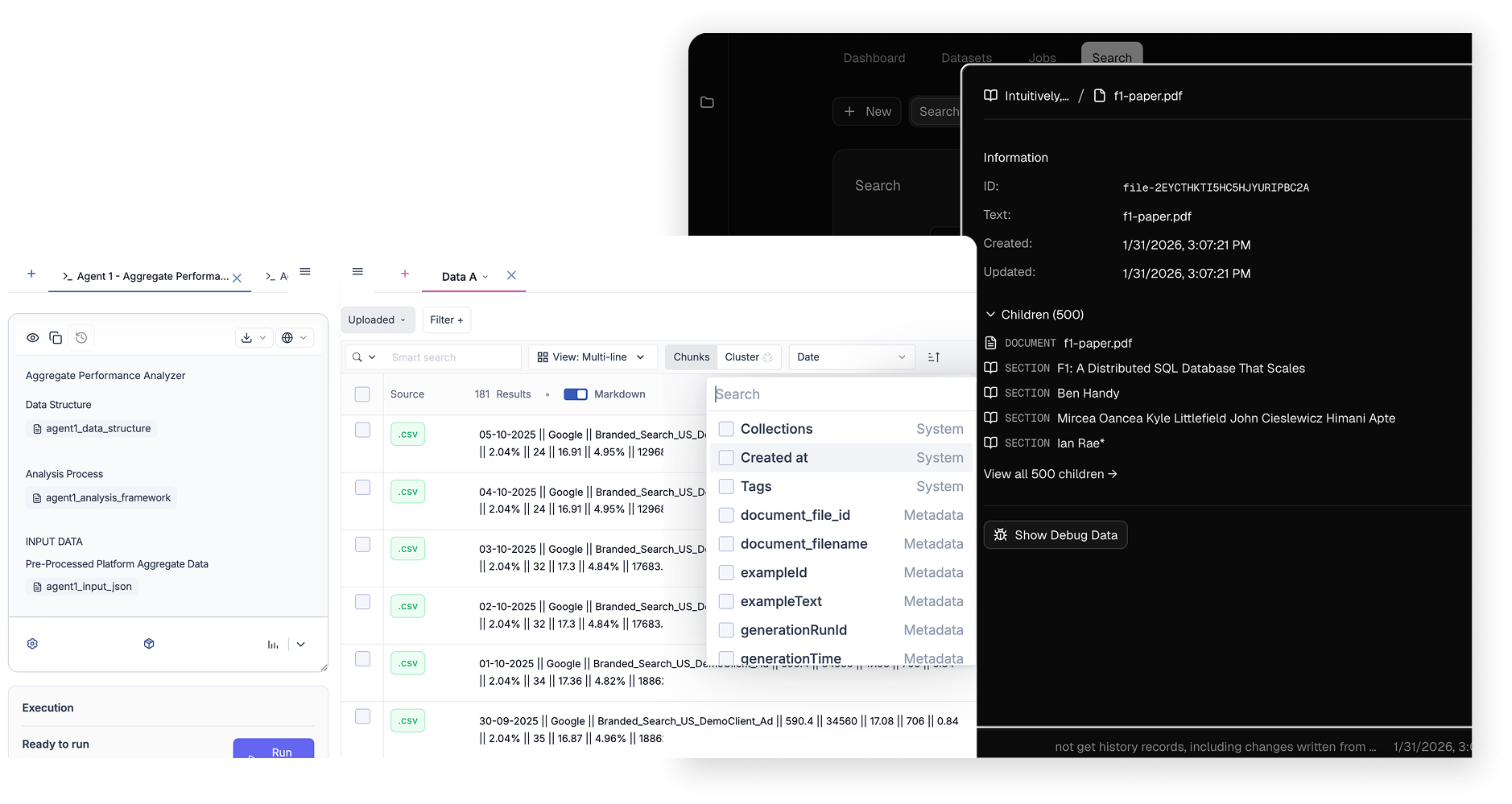
HumanFirst closes the gap between using AI and reliably incorporating AI into real work. Today valuable data lives across tools, but turning that data into consistent, high-quality AI behavior is manual, fragile, and irreproducible.
HumanFirst is a dedicated environment where organizations can transform data into governed, reusable AI behaviors. Our infrastructure enables product teams to ship differentiated AI features faster, professional services teams to quickly discover and deploy customer-specific solutions, and enterprise customers to safely customize and extend AI capabilities themselves as a scalable, evolving layer of organizational intelligence.
HumanFirst is for stakeholders building and deploying AI in products and workflows — product teams creating differentiated AI features; professional services teams delivering customized solutions with customer data; enterprise power-users who need to adapt and extend AI capabilities safely over time.
We're built for teams moving from experimentation to reliable AI outcomes. We help those teams ground models in real data, iterate rapidly, govern quality, and make AI capabilities reusable across users, customers, and applications.
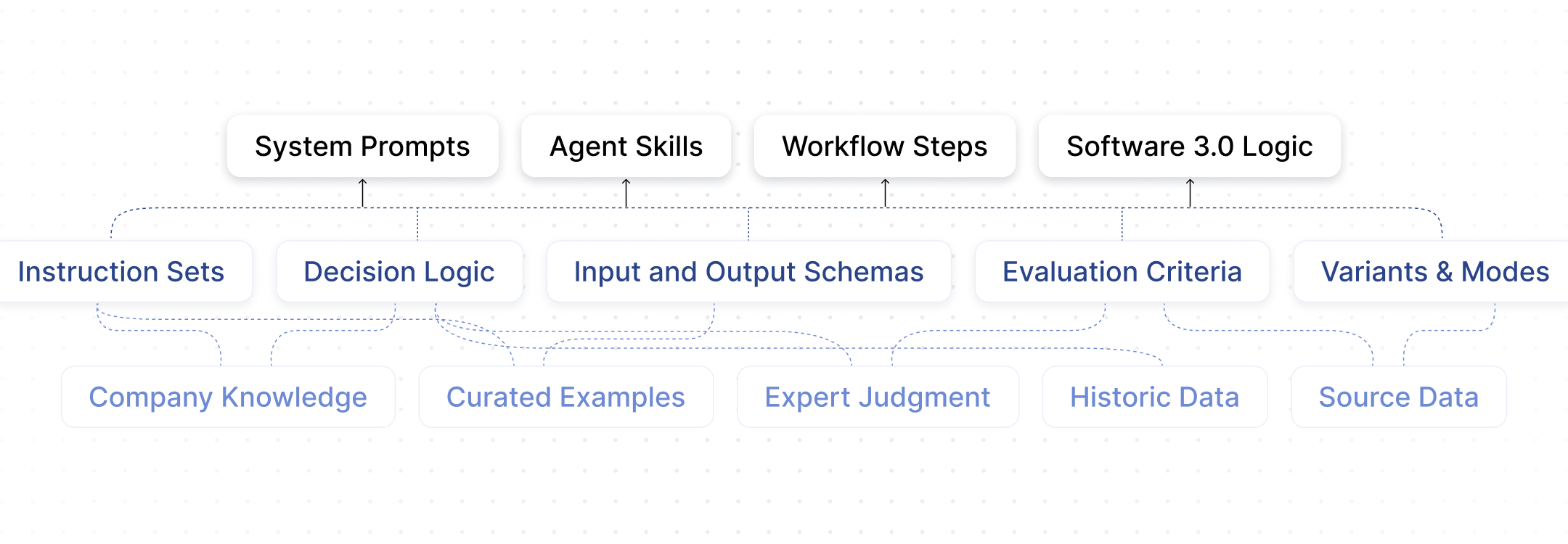
Existing AI tools are designed either for using AI or for engineering models, but not for systematically building and managing reusable AI behavior grounded in real organizational data.
Chat interfaces and copilots produce outputs that don’t persist or evolve, while developer frameworks and data pipelines require heavy engineering. Knowledge is lost, behavior is largely ungoverned, and customization is fragile and expensive; teams struggle to move from experimentation to reliable deployment.
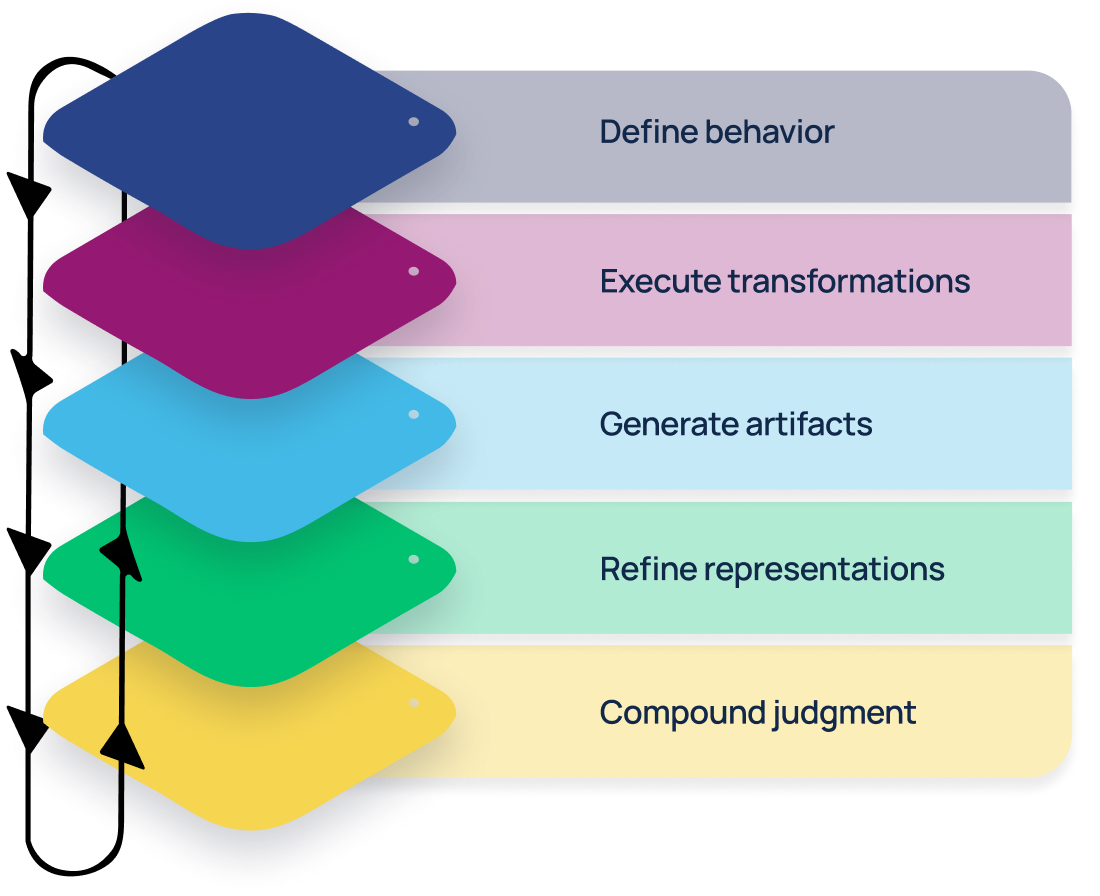
HumanFirst provides a dedicated layer where AI instructions, context, and transformations are iterated on, versioned, governed, and operationalized as durable capabilities across products and teams.
HumanFirst sits between foundation models and end-user applications as the AI behavior and control layer where organizational data, instructions, and expertise are assembled into reusable, governed AI capabilities before they’re executed inside products.
Models provide raw intelligence, applications provide user experiences, and HumanFirst manages how AI behaves, enabling teams to design, test, refine, and version the instructions, context, and transformations that turn generic models into reliable, domain-specific systems.
In your AI stack, HumanFirst is the system of record and development environment for AI behavior, bridging experimentation and production so AI capabilities can be consistently deployed, customized, and improved.
Book a demo with our team. We'll show you how HumanFirst works and how it fits into your AI stack.
AI behavior, controlled.